


Sommario
Introduzione
La ridondanza dei dati causata dalla presenza di istanze duplicate nello stesso database rappresenta un duplice problema: da una parte, lo spazio occupato inutilmente, dall’altra, la difficoltà di rendere univoche tali istanze e la possibile creazione di report e conteggi errati.
In questo articolo forniremo esempi delle più comuni soluzioni presenti sul mercato, e condivideremo la nostra personale prospettiva rispetto alla problematica che ci ha portati alla creazione di un prodotto scalabile, efficiente ed estremamente semplice.
Il problema dei dati duplicati
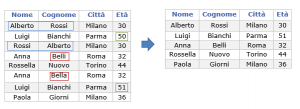
Un caso semplice e già largamente affrontato e risolto riguardo l’esistenza di dati duplicati nella stessa base dati aziendale è quello della rimozione di ridondanze di dati identici. Questo può capitare quando nel database aziendale vengono caricati dati legati alle stesse anagrafiche, ma provenienti da fonti diverse. In questo caso la stessa anagrafica potrebbe essere ripetuta più volte creando ridondanza inutile. L’eliminazione di tale ridondanza è relativamente semplice da effettuare, visto che i dati sono effettivamente identici.
Altro caso è invece quando la ridondanza è dovuta alla presenza di record ripetuti, con errori. In questo caso, le istanze sono registrate come differenti a causa di minime discrepanze in alcuni dei campi che le descrivono. In queste situazioni, che si presentano nella maggior parte delle basi dati, risulta molto più difficile deduplicare le ripetizioni, perché per farlo è necessario identificare l’errore.
Approcci tradizionali al problema dei dati duplicati
Data la centralità e la pervasione del problema, sono state sviluppate nel tempo diverse strategie di deduplica dei dati: partendo da quelle manuali, fino ad arrivare a sofisticati strumenti che sfruttano il machine learning.
Gli approcci più semplici al problema sono basati sulla correzione manuale delle stringhe. Si potrebbero per esempio creare dizionari di valori osservati nel tempo e riconosciuti come riconducibili alla stessa informazione.
Per esempio, i cognomi “Smith”, “Smaith”, “Smit” potrebbero venir inseriti in un vocabolario come rappresentativi della stessa persona. Il vocabolario creato sull’esperienza viene poi utilizzato per mezzo di operazioni logiche di tipo IF – THEN.
Per esempio, utilizzando SQL:
case [name]
when ‘Smit’ then ‘Smith’
Il problema principale di questa, e qualsiasi altra soluzione manuale è di essere poco efficiente in termini di tempistiche e scalabilità, e particolarmente sensibile ad errori di attenzione e distrazione.
Per quanto riguarda tool “pronti all’uso”, questi lavorano solitamente su campi specifici, per esempio gli indirizzi. Questi strumenti sono in grado di standardizzare i valori in maniera automatica, secondo regole prefissate. In questo caso il limite sta nella rigidità delle strutture impostate a priori, che per scenari aziendali reali rende gli strumenti non sufficientemente performanti per effettuare dedupliche precise su dati la cui struttura non è necessariamente quella “standard”.
Tra gli strumenti di machine learning proposti sul mercato per risolvere il problema dei dati duplicati, ce ne sono molteplici basati su algoritmi con logica fuzzy. Gli algoritmi basati su fuzzy logic si adattano bene al task di deduplica perchè sono in grado di accorpare dati sulla base della loro similarità, piuttosto che cercare match perfetti.
Il problema principale di questo approccio è la scarsa performance quando le differenze tra record sono minime da un punto di vista sintattico o di significato. In quest’ultimo caso si necessiterebbe di esperienza settoriale per essere in grado di capire che due valori molto simili sono effettivamente riconducibili alla stessa istanza, cosa che queste tipologie di algoritmi non sono in grado di fare.
Infine, se i dati da processare sono tanti, strategie di confronto con il metodo della forza bruta (bruteforce) non sono applicabili perchè impiegherebbero troppo tempo a produrre un risultato.
La soluzioni di Dataskills
Dataskills propone tramite il prodotto Matcher una soluzione che permette di identificare i record duplicati in modo automatico consentendo un notevole risparmio di tempo, nonchè un’efficienza superiore rispetto ad altre soluzioni. Le peculiarità del prodotto rispetto ad altre offerte presenti sul mercato sono:
- il tool è applicabile a qualsiasi tipologia di file o base dati
- il training è veloce e preciso
- l’architettura può essere scalata per lavorare con grandissime moli di dati
Lo strumento è utile sia per l’eliminazione di dati duplicati, che per effettuare operazioni di cross-matching tra tabelle che non hanno nessuna chiave identificativa in comune.
Per avere più dettagli riguardo a Matcher, visita la pagina dedicata al prodotto.
Comments are closed.




