

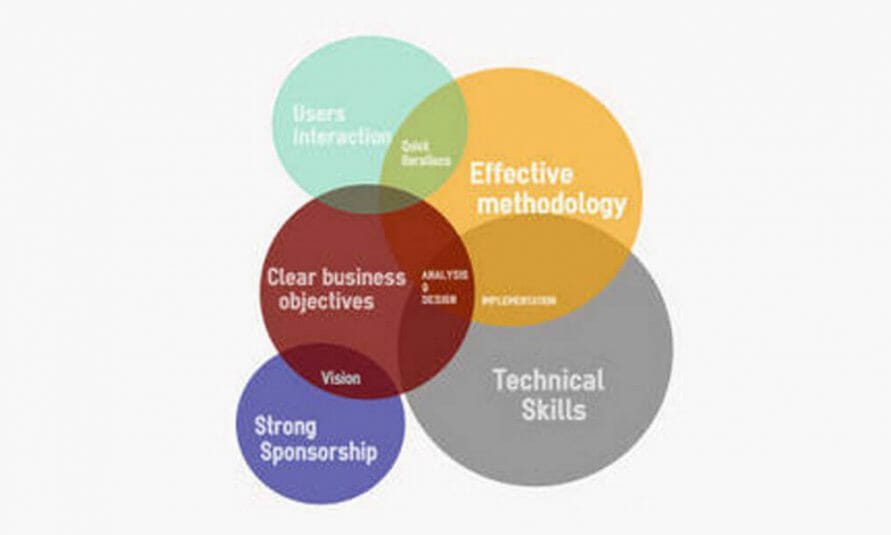
Abbiamo già evidenziato, attraverso un’infografica che la realizzazione di un progetto di Business Intelligence o di Predictive Analytics richiede la presenza di alcuni elementi in grado di determinarne la buona riuscita. La scheda evidenzia la competenza tecnologica e una metodologia efficace giochino una parte importantissima nella buona riuscita di un progetto. Altri fattori messi in evidenza sono:
- La presenza di una sponsorship forte: occorre un appoggio interno all’azienda in grado di sostenere il progetto e rimuovere gli ostacoli che le persone, a vari livelli, potranno porre.
- Interazione con gli utenti: a partire dalle fasi iniziali del progetto è assolutamente necessario avere un apporto di idee, commenti e considerazioni da parte degli utenti, al fine di raccogliere requisiti e problematiche nel modo più completo possibile.
- Chiarezza degli obiettivi di business: in ogni tipo di progetto è essenziale sia la comprensione del business, sia la presenza di obiettivi chiari e perseguibili.
Per i progetti di predictive e prescriptive analytics occorre fare attenzione anche ad altri aspetti che possono determinare la riuscita del progetto.
Chiarezza nei requisiti
Innanzitutto occorre avere un’idea molto chiara di ciò che si vuol ottenere dal sistema predittivo. Bisogna che il quesito da risolvere sia posto in maniera chiara, in modo che l’algoritmo di machine learning possa estrarre risultati che non siano in alcun modo ambigui. Un esempio di domanda mal posta potrebbe essere: “come posso aumentare i ricavi?”; tale domande è troppo generica e si tratta di un quesito irrisolvibile attraverso un modello di machine learning. Invece domande mirate come la seguente, sono ottimali per un sistema di machine learning: “quali clienti abbandoneranno la nostra azienda per servirsi di un fornitore diverso?”.
Qualità dei dati
Un altro punto di fondamentale importanza riguarda l’accuratezza dei dati: è impensabile infatti ottenere buoni risultati prendendo come punto di partenza dati che contengano errori o valori mancanti. È essenziale che la qualità dei dati sia la migliore possibile e che le soglie di errore siano ridotte al minimo.
Quantità dei dati
Se è vero che la qualità dei dati è fondamentale per la riuscita di progetti di machine learning, anche la quantità dei dati gioca un ruolo molto importante. Più dati significa più dettagli e maggior sicurezza (confidenza) di cogliere i pattern nascosti. Possiamo affermare che un algoritmo con mediocri capacità predittive, ma con a disposizione molti dati (accurati), produce risultati migliori di un buon algoritmo che però sia eseguito su una scarsa quantità di dati. Nel primo caso infatti, la maggior quantità di dati consente una più elevata generalizzazione, che è la chiave per ottenere un modello efficace.
Selezione e preparazione degli attributi
Un altro fattore che determina la riuscita di un progetto di machine learning è la scelta degli attributi (features) che entrano nel modello come input. Potrebbero esservi attributi tra loro fortemente correlati, oppure, gli attributi potrebbero essere espressi in un formato che non è adatto agli algoritmi di machine learning. I dati sono quindi da preparare, per esempio con normalizzazioni, discretizzazioni, trasformazioni di variabili categoriche in variabili numeriche tramite la creazione di nuove variabili binarie, ecc.). Ancora più spesso gli attributi sono da ricavare a partire dai dati “grezzi”. Per esempio, in un progetto di machine learning in ambito bancario volto a determinare i clienti con alta probabilità di abbandono (i churners), non è conveniente utilizzare i valori dei movimenti di conto corrente o del deposito titoli così come sono; da essi invece occorre ricavare una serie di attributi più adatti agli algoritmi di classificazione. Nel nostro esempio, un paio di tali attributi potrebbero essere: il numero di operazioni di prelievo con bancomat (nell’ultimo mese, negli ultimi 6 mesi, ecc), il numero di utilizzi della carta di credito (nell’ultimo mese, negli ultimi 6 mesi, ecc), e così via.
In generale, il tempo dedicato alla preparazione dei dati (raccolta, integrazione, trasformazione, creazione di attributi) è di gran lunga superiore a quello di set up, training e verifica degli algoritmi.
Conclusioni
Nei progetti di machine learning, accanto ai fattori critici tipici dei progetti di Business Intelligente, assumono una notevole importanza anche altri aspetti (la chiarezza dei requisiti, la qualità dei dati, la quantità dei dati, la fase di preparazione), senza i quali non potranno essere raggiunti i risultati desiderati.
Comments are closed.