


L’ Analisi Predittiva, precedentemente conosciuta come Data Mining, è un termine che raccoglie le varie tecniche di Machine Learning utilizzate con il fine di desumere informazioni utili per il proprio business, dal patrimonio dati aziendale.
L’Analisi Predittiva, in inglese Predictive Analytics, si basa principalmente su:
- Esistenza di una base di dati storici, che viene studiata per capire quali interazioni tra variabili di input hanno causato un certo output
- Necessità di prevedere quale sarà lo stato dei fatti nel futuro
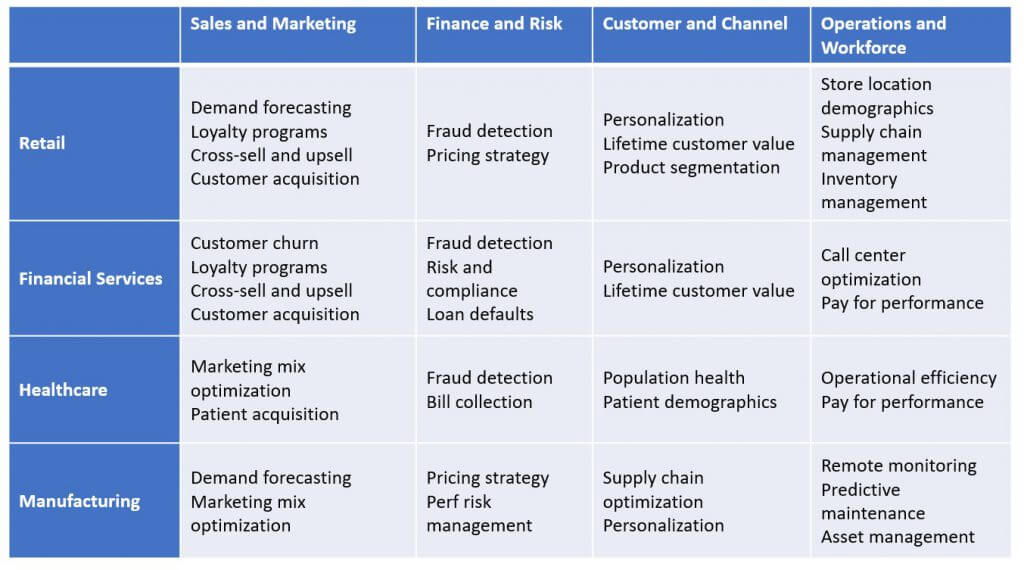
Nella tabella che segue, cercherò di riassumere quali sono gli ambiti di applicazione dell’Analisi Predittiva, e che tipo di modelli possono essere sfruttati da quali tipi di business.
E’ da sottolineare che l’utilità di questi strumenti discerne dal fatto che, se strutturati nel modo giusto, i modelli di Analisi Predittiva sono in grado di rispondere a tantissimi quesiti di business, e risolvere le problematiche aziendali in modo ottimale.
La lista è quindi solo una spunto da cui partire, ricordandosi che nel settore della Data Science c’è molto spazio per la creatività: un esperto Data Scientist utilizza molteplici tecniche per creare modelli ad-hoc per diverse realtà aziendali.
Per maggiori esempi consultare l’articolo “ Data Mining Esempi”.
Che tipi di problemi aziendali possiamo risolvere con modelli predittivi?
Possiamo distinguere quattro macroclassi di modelli di Analisi Predittiva:
- classificazione
- regressione
- clustering
- market basket analysis
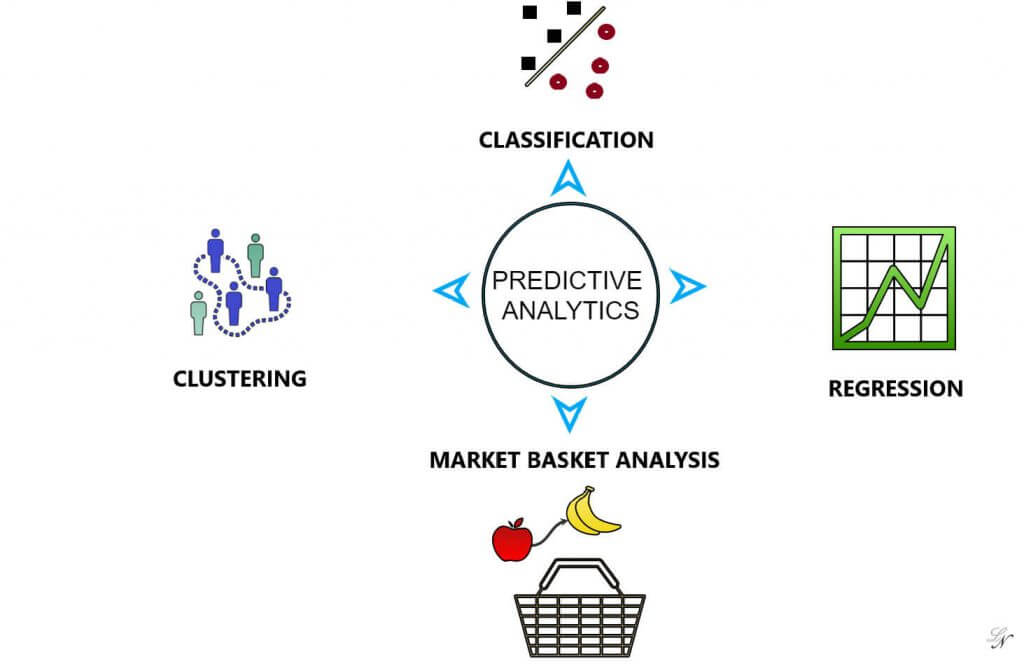
Classificazione e regressione sono due tipi di modelli supervisionati: ovvero modelli per cui abbiamo, per i dati raccolti nel passato, la risposta al quesito a cui vogliamo rispondere.
Market Basket Analysis e Clustering sono invece modelli non supervisionati: storicamente non abbiamo una risposta al quesito a cui vogliamo rispondere.
Modelli supervisionati e non supervisionati differiscono rispetto al modo in cui il problema di Machine Learning viene strutturato.
Classificazione
La Classificazione, classification, è una tecnica di Analisi Predittiva utilizzata quando vogliamo suddividere la nostra base dati in classi:
- la transazione è una frode oppure no? (frode vs. non frode)
- il cliente è un churner oppure no? (cherner vs. non churner)
- il prodotto è difettoso oppure no? (difetto vs. non difetto)
- a quale tipologia di difetto appartiene un prodotto difettoso? (difetto A vs. difetto B vs. difetto C)
Regressione
La Regressione,regression, è una tecnica di Analisi Predittiva utilizzata quando vogliamo stimare il valore atteso in futuro:
- quanta sarà la domanda per i nostri prodotti nei prossimi 7 giorni?
- quale sarà il prezzo dell’energia elettrica nei prossimi 30 giorni?
La differenza tra le tipologie di output scaturite da queste due diverse tecniche di analisi dei dati richiederanno l’utilizzo di differenti metriche di performance per testare la bontà del modello.
E’ importante comprendere che, partendo da una base dati, si possono porre sia quesiti di Classificazione che quesiti di Regressione. Per esempio, con una base dati che descrive la nostra produzione, possiamo chiedere:
- il prodotto è difettoso? (classificazione binaria)
- che tipo di difetto riporta il prodotto? (classificazione multi-classe)
- di che entità è il difetto, in millimetri? (regressione)
Clustering
Il Clustering è una tecnica di Analisi Predittiva di tipo non supervisionato, che si prefigge di suddividere la base dati aziendale in gruppi omogenei. Ogni gruppo ha caratteristiche simili, diverse da quelle degli altri gruppi.
Per esempio:
- quanti e quali gruppi esistono nella mia clientela, che hanno preferenze e comportamenti di acquisto simili?
Market Basket Analysis
La Market Basket Analysis è una tecnica utilizzata dalla maggior parte delle piattaforme di vendita e servizi online che utilizziamo ogni giorno: Amazon, Ebay, Spotify, Expedia, e svariate altre. Lo scopo della Market Basket Analysis è di consigliare ai propri clienti quale bene o servizio acquistare. Questo viene fatto sulla base del comportamento di acquisto passato, e le preferenze espresse.
Per esempio:
- in passato hai visitato il locale X e il ristorante Y, ti potrebbe piacere anche Z
Software analisi predittiva: quali si utilizzano per creare modelli predittivi?
Nei decenni passati sono stati creati svariati linguaggi di programmazione, che miglioravano incrementalmente il linguaggio predecessore, soprattutto per quanto riguarda la facilità di utilizzo.
Il primo linguaggio di programmazione definito di “alto livello”, ovvero più vicino al linguaggio umano, è stato C, inventato da Dannis Ritchie all’interno dei laboratori Bell, nel 1972.
Sempre nel 1972 viene introdotto un altro linguaggio tutt’ora molto utilizzato, soprattutto per quanto riguarda la Data Preparation preliminare all’analisi predittiva: SQL, creato da Donald D. Chamberlin e Raymond F. Boyce di IBM.
Attualmente, due dei software di analisi predittiva al momento più utilizzati nel mondo della Data Science sono Python e R, introdotti rispettivamente nel 1991, da Guido Van Rossum, e nel 1993 da Ross Ihaka e Robert Gentleman.
R è nato come software statistico, ma presto esteso ad applicazioni di data modeling e analisi predittiva. Python si è subito instaurato come uno dei linguaggi più facilmente approciabili, data la facilità di lettura e di utilizzo. Inoltre offre una moltitudine di pacchetti per l’analisi predittiva, e anche per il Deep Learning.
Sia R che Python sono Open Source, caratteristica che ne facilita ulteriormente l’apprendimento ed utilizzo, data la grande quantità di risorse disponibili gratuitamente sul web.
Corsi di analisi predittiva, come avvicinarsi all’analisi avanzata dei dati
Il ruolo del Data Scientist è sempre più importante: in ogni tipo di azienda e in qualsiasi settore, anche i più tradizionali. Questo perché, come si diceva all’inizio, il fatto di poter estrarre informazioni dal proprio patrimonio di dati è un’immensa fonte di valore, economico e competenziale.
In Italia, la figura del Data Scientist, e la Data Science, hanno cominciato ad acquisire centralità negli ultimi anni, mentre in altre parti del mondo, soprattutto negli Stati Uniti, il mercato è già più avanzato.
Per chi si avvicina ora alla Data Science esistono tre principali tipi di risorse:
- risorse online: video, webinars, corsi online, articoli
- libri
- corsi offline
Per ognuna di esse, bisogna fare sempre attenzione a scegliere le fonti giuste. E’ quindi fondamentale poter confutare con un esperto in materia il valore del materiale consultato.
→ Hai bisogno di consulenza? scegli la nostra consulenza di Analisi Predittiva.
Analisi predittiva libro
Per acquisire una comprensione dettagliata e omnicomprensiva di varie tematiche legate all’analisi dei dati consiglio il libro: “Big Data Analytics: il manuale del Data Scientist” di Alessandro Rezzani. Rezzani è stato uno dei primi Data Scientist in Italia, nonchè ricercatore presso l’Università Commerciale Bocconi di Milano, dove è tutt’ora docente.
Scarica il capitolo del libro “Big Data Analytics: il manuale del Data Scientist”
Comments are closed.