


Con il termine Data Mining, conosciuto negli ultimi anni come Analisi Predittiva, si intende l’applicazione di algoritmi di Machine Learning a basi di dati, con il fine di estrarne informazioni di valore per il business. Differentemente dalle analisi statistiche tradizionali, che si limitano a riorganizzare lo storico di dati raccolti nel tempo, l’analisi di dati tramite Data Mining sfrutta i dati storici per fornire previsioni sullo stato dei fatti nel futuro.
Data mining: esempi pratici
Cercherò di essere più chiara con alcuni esempi pratici.
Churn Analysis
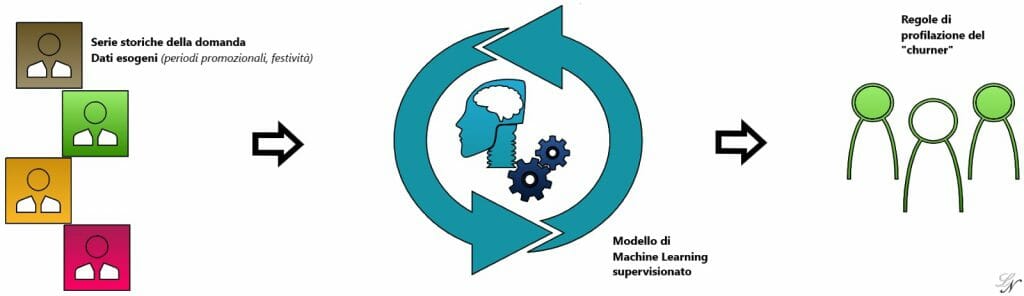
L’analisi dei churners, ovvero clienti che abbandonano il proprio provider di un certo servizio per passare alla concorrenza, ha lo scopo di identificare quali sono le caratteristiche salienti di un cliente che passerà alla concorrenza nel futuro. Le “regole decisionali” desunte dal modello di Data Mining, ovvero quelle regole che ci permetteranno di riconoscere chi tra i nostri clienti potrebbe passare alla concorrenza, sono il più delle volte regole articolate, basate sull’effetto simultaneo di svariate caratteristiche descrittive del cliente.
Il nostro modello di Data Mining ci fornirà una profilazione dettagliata del “churner”, specifica per la nostra base dati, basata su vari tratti comportamentali desunti studiando le casistiche passate.
Essere in grado di individuare le caratteristiche di un potenziale churner è fondamentale per avanzare azioni preventive che dissuadano il cliente dal passare alla concorrenza.
Fraud Detection
Il riconoscimento di transazioni fraudolente si realizza analizzando uno storico di transazioni, con il fine di ottimizzare il modello di Data Mining così che sia in grado di identificare quali tratti della transazione sono importanti per poterla definire come fraudolenta.
In questi tipi di analisi la difficoltà maggiore è rappresentata dalla sproporzione, nello storico di dati, delle transazioni non fraudolente rispetto a quelle fraudolente. Questo problema si può mediare utilizzando tecniche di ribilanciamento.
Anche in questo caso la vera forza del modello di Data Mining è desumere un insieme di regole tramite le quali possiamo profilare le tipologie di transazioni fraudolente, e soprattutto possiamo identificare quali caratteristiche hanno maggior potere predittivo. Proprio su queste caratteristiche andremo a focalizzarci in futuro, per bloccare e controllare più dettagliatamente quelle transazioni che hanno le stesse caratteristiche di altre viste in passato, di carattere fraudolento.
Essere in grado di individuare le caratteristiche di una transazione fraudolenta è fondamentale per bloccare solo quelle transazioni che hanno alta probabilità di essere frodi, piuttosto che dover bloccare anche tante transazioni che si scopre poi non essere di carattere fraudolento.
Time series Forecast
I modelli di regressione utilizzano tecniche di Data Mining per predire il valore futuro di ciò che per il nostro business è utile monitorare. Per esempio il prezzo dei prodotti che vendiamo, la quantità di energia utilizzata nei nostri processi produttivi, i costi di produzione.
Monitorando i cambiamenti in questi ed altri valori, possiamo allenare un modello di Data Mining con lo scopo di essere in grado di predire in che modo queste serie di prezzi, costi, o valori, varieranno nel futuro.
In questo modo possiamo fare delle stime molto più precise di quelli che saranno i costi futuri, le risorse energetiche necessarie, e potremo gestire campagne promozionali e di marketing sulla base dei cambiamenti di prezzo previsti.
Essere in grado di predire il comportamento di una serie storica è fondamentale per:
- bloccare i prezzi delle risorse necessarie, per esempio il prezzo dell’energia acquistata
- stimare in modo più preciso ricavi e costi
- in generale allocare le risorse in modo più efficiente
Clustering
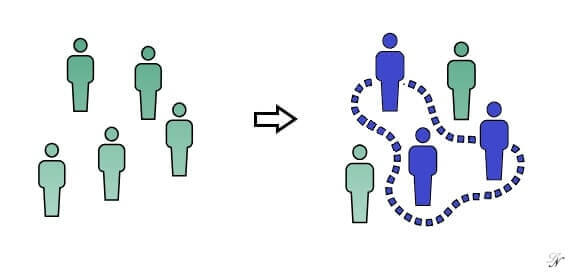
Differentemente dalle due casistiche trattate precedentemente, che sono solitamente analisi di tipo supervisionato, il clustering utilizza il Data Mining per segmentare la base dati senza avere una conoscenza a priori della “risposta corretta” al quesito posto.
Un esempio molto comune è la segmentazione della propria clientela, per la quale però non si sa quanti e quali segmenti siano presenti. Sarà invece il modello a suggerirci in che modo si possono segmentare i nostri clienti, e sulla base di quali caratteristiche.
Nonostante questa analisi sia quasi sempre di tipo non supervisionato, l’output del modello di Data Mining è comunque un insieme di regole, o attributi, che identificano i profili, in questo caso dei diversi gruppi di clienti.
Segmentare la clientela con l’ausilio di regole articolate è fondamentale per:
- offrire prodotti e servizi mirati ai diversi gruppi
- creare campagne promozionali e di marketing ad hoc per i diversi gusti e preferenze
- in generale allocare le risorse in modo più efficiente
Market Basket Analysis
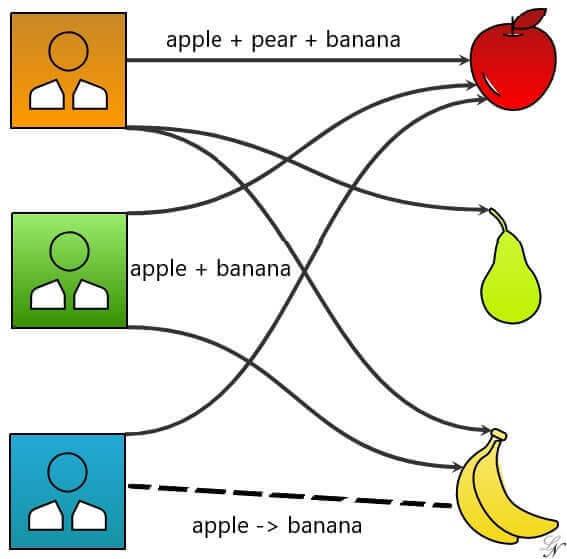
La Market Basket Analysis è un’altra tipologia di analisi non supervisionata che utilizza il Data Mining con lo scopo di suggerire ai propri clienti quali beni o servizi potrebbero essere di loro gradimento, sulla base delle preferenze espresse in passato e presenti nella base dati.
Ci sono svariati modi per creare modelli per la Market Basket Analysis, tutti accomunati dal fatto che in output vengono forniti dei consigli di acquisto per ciascuno dei propri clienti (effettivi o anche potenziali).
L’utilizzo del Data Mining per la Market Basket Analysis è fondamentale per:
- aumentare la customer satisfaction, perchè il cliente apprezzerà il fatto che gli vengano suggeriti prodotti che effettivamente incontrano i suoi bisogni e preferenze
- aumentare la customer retention, perchè il cliente vede i suggerimenti mirati come un forte differenziatore rispetto a una concorrenza che non utilizza strumenti di analisi avanzata dei dati
Comments are closed.