


È il 1972 e gli psicologi Amos Tversky e Daniel Kahneman (premio Nobel per l’Economia nel 2002) propongono un primo studio scientifico di quelli che vengono formalmente definiti come “Bias cognitivi”, fallacie sistematiche nel pensiero umano che conducono a scelte e giudizi che si discostano dalla razionalità.
Da quel momento, la ricerca si è a lungo occupata di questo tipo di Bias e ne ha identificati diversi che, impattando implicitamente il modo di ragionare degli individui, ne influenzano il comportamento, e possono condurre in ultima istanza a decisioni peggiori.
Essi non sono comunque da considerare necessariamente un male per il genere umano, essendo il frutto del processo evolutivo che ci ha richiesto, nel corso della storia, di prendere decisioni rapide in contesti di informazione incompleta. Tipicamente infatti, un Bias cognitivo altro non è che un procedimento non rigoroso – o euristico – che consente alla nostra mente di abbreviare il processo di valutazione razionale e di prendere decisioni più rapide.
Essere a conoscenza di questi Bias cognitivi è quindi fondamentale in moltissimi ambiti, dalla psicologia alla finanza e all’economia comportamentale, fino ad arrivare anche alla Data Science.
Nel progettare modelli predittivi che possano aiutare l’uomo a prendere decisioni in modo automatizzato o semi-automatizzato è infatti molto importante conoscere questi bias per evitare che scelte soggettive basate su fallacie logiche possano in qualche modo distorcere i risultati dei modelli, incorporando gli errori dell’intelletto umano negli output delle previsioni e suggerendo strategie fallimentari.
Non solo, di estrema importanza è anche evitare che tali errori possano essere commessi nell’interpretazione dei dati e dei risultati dei modelli, in un procedimento che pur quanto possa essere coadiuvato dall’Intelligenza Artificiale, rimane in molti casi altamente soggettivo.
Vediamo quindi alcuni esempi dei più comuni Bias cognitivi:
Status Quo Bias
Questo bias, la cui esistenza è stata empiricamente dimostrata nel 1988, si riferisce al fenomeno per il quale in un insieme di possibili scelte, una delle opzioni diventa significativamente più preferibile solo per il fatto di essere quella che rappresenta la situazione di partenza.
In altre parole, in situazioni di incertezza la nostra mente tende a preferire la scelta più familiare e a percepire implicitamente come “più rischiosa” una scelta che si discosta dalla situazione di partenza.
Gli esseri umani avrebbero quindi una tendenza a preferire scelte passive (status quo) rispetto a scelte attive che richiedono un cambiamento rispetto alla situazione iniziale.
Nell’esperimento originale del 1988 ai soggetti intervistati venne chiesto di rispondere ad una situazione ipotetica nella quale erano presenti diverse opzioni per scegliere come investire una somma di denaro ricevuta in eredità.
Se ai soggetti veniva detto che tale somma era già investita (ad esempio in azioni a basso rischio), la maggior parte degli intervistati preferiva mantenere l’alternativa iniziale piuttosto che scegliere un’opzione diversa per l’allocazione del denaro (come titoli di stato, obbligazioni o azioni a più alto rischio).
La preferenza per la scelta di “default” si riflette in molti casi pratici (è il motivo, ad esempio, per il quale quando installiamo un’applicazione o un software siamo portati a mantenere le opzioni di default), e può quindi essere incorporata nei dati, producendo possibili distorsioni. Tale bias rappresenta quindi un fattore importante da considerare nel valutare le preferenze degli individui verso una determinata scelta.
Rappresentatività e ampiezza del campione
Considerate il seguente problema:
“In una città vi sono due ospedali, uno grande e uno piccolo. Nell’ospedale grande nascono ogni giorno 100 bambini, nell’ospedale piccolo 20. Le probabilità che il neonato sia maschio o femmina sono, ovviamente, entrambe pari al 50%.
Tuttavia, nel corso di un anno vi sono giorni in cui il numero dei neonati maschi è pari o superiore al 60%.
Sulla base di queste informazioni, tali giorni (con almeno il 60% di nati maschi) si verificheranno più frequentemente:
- a. Nell’ospedale grande
- b. Nell’ospedale piccolo
- c. All’incirca in egual misura in entrambi gli ospedali ”
La risposta esatta è la b., nell’ospedale più piccolo è statisticamente più probabile che vi sia una maggiore variabilità, mentre nell’ospedale più grande è ragionevole pensare che sia molto più facile avere un numero di nati maschi più vicino al 50%, essendo il campione più grande. Tuttavia, a questo esperimento, i cui risultati furono pubblicati nel 1974, la maggior parte delle persone rispose c., e solo il 22% degli intervistati scelse la risposta corretta. Questo è dovuto al problema di insensibilità all’ampiezza del campione, un bias cognitivo che intuitivamente ci porta a non considerare accuratamente il campione statistico.
Effetti simili sono quelli che portano intuitivamente a trarre conclusioni generali su un campione basato su poche osservazioni. Ad esempio, potremmo essere indotti a pensare che un fondo di investimento che millanta un rendimento del 20% annuo sia un ottimo fondo. Tuttavia, se tale fondo è in attività solamente da 3 anni, significa che stiamo basando le nostre conclusioni su un campione di osservazioni estremamente ridotto e i gestori del fondo potrebbero essere stati solamente fortunati.
Nell’economia e nella finanza comportamentale, questo bias è anche noto come Sample Size Neglect, e come gli altri bias legati all’ampiezza del campione corrisponde ad una fallacia logica che deriva dall’euristica di rappresentatività, una delle più famose “scorciatoie mentali” che ci inducono in errore.
Trarre una conclusione sulla base di poche osservazioni può quindi rivelarsi controproducente ed è importante che nel processo decisionale si consideri accuratamente la natura del campione utilizzato.
Correlazione non implica causalità
Immaginando di avere due eventi A e B fortemente correlati tra loro, siamo naturalmente portati a credere che vi sia un nesso causale tra essi, ossia che B sia il frutto di A o viceversa. Tuttavia, non necessariamente due eventi strettamente correlati sono in rapporto causale fra loro. La correlazione potrebbe essere infatti totalmente casuale o potrebbe esserci un terzo fattore C (di cui non siamo direttamente a conoscenza) che è causa di entrambi.
Esempio:
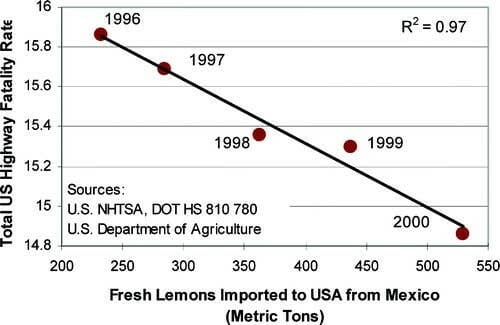
Modello di regressione lineare dove il tasso di mortalità sulle autostrade statunitensi è visto come funzione delle importazioni di limoni dal Messico
Questa regressione lineare (vedi immagine) sembra apparentemente suggerire che l’aumento delle importazioni di limoni messicani si traduca in una riduzione del numero di incidenti stradali mortali negli Stati Uniti, essendo i due fenomeni fortemente in correlazione negativa fra loro.
Ovviamente, non vi è alcun nesso di causalità e la alta “capacità predittiva” di questo modello altro non è che il semplice frutto del caso.
Un altro esempio che viene spesso citato in merito è la forte correlazione tra morti accidentali avvenute in piscina e il consumo pro capite di gelati. Tra i due fenomeni non vi è alcun nesso di causalità, ma sono entrambi causati da una variabile omessa che è l’aumento della temperatura, prodotto dall’arrivo dell’estate. Tale tipo di fallacia è anche nota come distorsione da variabili omesse (omitted variables bias).
Simile è anche la fallacia post-hoc (dal latino Post hoc ergo propter hoc, ossia “dopo ciò, quindi a causa di ciò”) secondo cui siamo portati a credere che un evento B, essendo avvenuto in seguito all’evento A, ne sarebbe la diretta conseguenza. (Se starnutisco e la luce si spegne, sono portato a credere che il mio starnuto abbia causato il blackout, quando invece non vi è alcun legame tra i due eventi).
Anche questo bias è quindi da tenere in considerazione quando si esaminano i risultati di un modello predittivo. Fattori che appaiono fortemente correlati tra loro potrebbero non presentare alcun nesso causale o essere entrambi il prodotto di un terzo fattore che non è stato considerato in partenza.
Pregiudizio di sopravvivenza (Survivorship Bias)
Il Pregiudizio di sopravvivenza o Survivorship Bias è una fallacia logica per la quale siamo naturalmente portati a sovrastimare i casi di successo rispetto ai fallimenti.
Un tipico esempio è quello degli aerei americani nella Seconda Guerra Mondiale. In un primo momento, osservando i fori dei proiettili degli aerei che rientravano dalle missioni, la strategia adottata era quella di rinforzare le parti dell’aereo più colpite. Tuttavia, questa strategia non teneva conto del fatto che i fori dei proiettili osservati si basavano solo sui velivoli che erano sopravvissuti, mentre non consideravano gli aerei che erano stati abbattuti. Lo statistico Abraham Wald, grazie ai suoi studi sul Survivorship bias, propose quindi di rinforzare le zone dell’aereo che presentavano meno danni, essendo quelle probabilmente più colpite negli aerei che non rientravano alla base. La strategia si rivelò vincente e permise di ridurre il numero di aerei abbattuti.
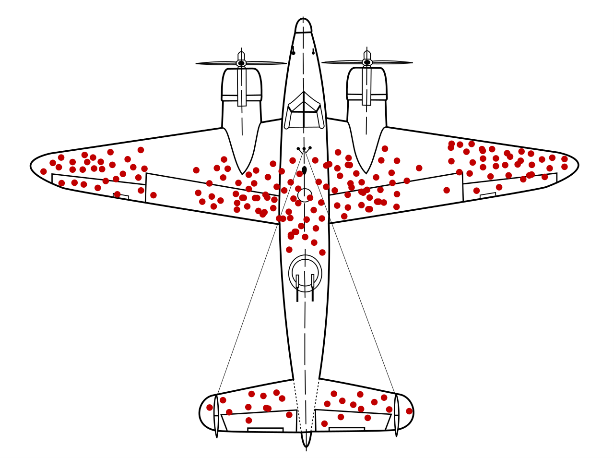
Le parti più colpite negli aerei sopravvissuti sono quelle non vitali
Un altro esempio può essere quello degli imprenditori di successo. Mark Zuckerberg, Steve Jobs e Bill Gates sono tra i più noti imprenditori di successo della storia e hanno in comune il fatto di aver abbandonato l’università per dedicarsi alle proprie aziende.
Questo significa che per diventare imprenditori di successo bisogna lasciare l’università?
Se consideriamo i casi dei fondatori di Facebook, Apple e Microsoft saremmo forse portati a credere di sì, ma in realtà stiamo traendo le nostre conclusioni senza considerare almeno altrettanti casi di fallimento (di cui magari non siamo a conoscenza, essendo poco noti o sconosciuti).
In molti casi quindi il successo di determinate persone, aziende o strategie può portarci a valutazioni scorrette che non tengono conto dei casi di fallimento, che possono non essere noti e, di conseguenza, sottostimati nelle nostre valutazioni.
Come evitare di cadere in errore quando si lavora con i dati?
Un primo step è sicuramente quello della consapevolezza. Essere a conoscenza dei bias cognitivi può essere di aiuto nel valutare l’efficacia di un modello o nell’elaborazione di strategie basate sui dati.
Oltre a mantenere sempre uno spirito critico è anche importante essere meticolosi nei processi di raccolta dei dati, che devono essere propriamente ordinati e rispettare le regole di Data Quality.
- Il campione raccolto è sufficientemente rappresentativo?
- Le domande del questionario che ho somministrato ai miei clienti sono formulate in modo appropriato?
- Da dove provengono i dati? Si tratta di fonti affidabili?
Queste sono alcune delle domande che è importante farsi per evitare che le fallacie appena descritte possano entrare in gioco, producendo risultati distorti.
Infine, un approccio sperimentale, dove si tenga traccia delle possibili alternative e si testi il successo di determinate azioni, può rivelarsi la scelta vincente nella maggior parte dei casi.
Se hai bisogno di una consulenza dedicata su uno o più servizi da noi offerti, non esistare a scriverci.
Contattaci subito
Per approfondire:
- Analisi Predittiva: possibili ambiti di applicazione
- L’ottimizzazione dell’offerta tramite algoritmi predittivi
- IoT, Intelligenza Artificiale e sostenibilità: come la tecnologia ci aiuta a prenderci cura del nostro pianeta
Fonti:
Kahneman, D., & Tversky, A. (1972). Subjective probability: A judgment of representativeness. Cognitive psychology, 3(3), 430-454.
Kahneman, D., Knetsch, J. L., & Thaler, R. H. (1991). Anomalies: The endowment effect, loss aversion, and status quo bias. Journal of Economic perspectives, 5(1), 193-206.
Tversky, A., Kahneman, D. (1974). Judgment under uncertainty: Heuristics and biases. Science. 185 (4157): 1124–1131.
Richard H. Thaler, Cass R. Sunstein (2008). Nudge: Improving decisions about health, wealth, and happiness.
Comments are closed.