



In un precedente articolo, abbiamo presentato il Data Lake, una repository per dati strutturati e non strutturati per la gestione del patrimonio dati aziendale, che grazie alla sua flessibilità è capace di adattarsi a contesti diversi con ottime performance.
Questo tipo di architettura, nonostante sia il non plus ultra per conservare dati in diversi formati e per condurre attività di Analytics avanzate (come clustering o analisi predittiva), comporta spesso diverse sfide rispetto a soluzioni di Business Intelligence più tradizionali come i Data Warehouse.
Normalmente infatti, il Data Lake richiede competenze più avanzate e un’attenta governance per non correre il rischio di trovarsi in una palude di informazioni inutilizzabili (la cosiddetta “Data Swamp”).
A tal proposito, una tecnologia che può essere determinante nel risolvere questo tipo di problemi è sicuramente rappresentata da Databricks Delta.
Che cos’è Databricks Delta?
Lanciata nel 2017, Databricks Delta è definita come “unified data management system to simplify large-scale data management”[1] ossia come una tecnologia adatta a semplificare la gestione di grandi volumi di dati.

Fonte: Databricks.com
Databricks Delta è basata sul Delta Lake, un particolare formato utilizzato da Spark per lo storage dei dati su un Data Lake (che può essere ad esempio Azure Data Lake Store o Amazon S3). Attraverso il Delta Lake è possibile garantire l’integrità dei dati attraverso transazioni di tipo ACID (Atomic, Consistent, Isolated and Durable) e allo stesso tempo offrire la possibilità di eseguire operazioni di reading e writing senza compromettere le performance.
Sfruttando la potenza di calcolo di Apache Spark, il Delta Lake garantisce la possibilità a più utenti di scrivere e leggere una tabella nello stesso momento. Per mostrare la corretta versione dei dati in questo caso il Delta Lake utilizza un transaction log, dove vengono tracciati tutti i cambiamenti che i vari utenti hanno effettuato sulla tabella.
Quando infatti un utente legge una tabella per la prima volta o avvia una query su una tabella che è stata modificata dalla sua ultima lettura, Spark controlla il transaction log per vedere se sono state effettuate nuove modifiche e aggiorna la tabella dell’utente con l’ultima versione. In questo modo si ha la certezza che l’ultima versione della tabella sia sempre sincronizzata e che gli utenti non possano fare modifiche che entrino in conflitto tra loro.
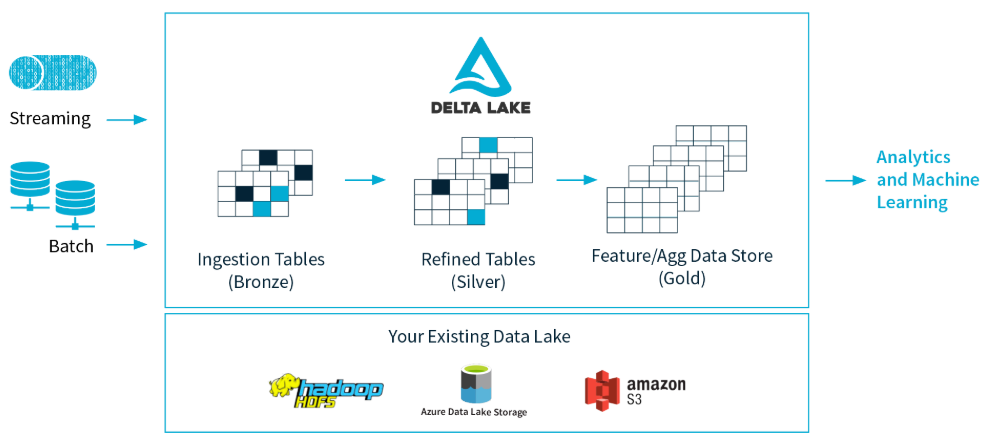
Fonte: Databricks.com
Quali sono i vantaggi di Databricks Delta per il Data Lake?
Come abbiamo già sottolineato, implementare un Data Lake è un compito tutt’altro che semplice e vi sono diverse sfide che devono essere affrontate se si vuole sfruttare appieno la potenza di quest’architettura.
In questo senso, il formato Delta Lake di Databricks può essere la scelta vincente in diverse situazioni.
Vediamone alcune:
Gestione dei Metadati
Il Data Lake è pensato per accentrare al suo interno dati con strutture molto diverse fra loro. All’interno della repository è possibile conservare dati strutturati, provenienti dal gestionale ERP, come le tabelle delle anagrafiche dei clienti, e dati non strutturati o semi-strutturati, come video, immagini o documenti provenienti dal web. Con tutti questi dati spesso è difficile tenere traccia del tipo di dato presente nel Data Lake e dei vari passaggi che concorrono alla sua trasformazione prima dell’utilizzo finale.
Grazie al Delta Lake, è possibile utilizzare il transaction log per verificare i metadati all’interno di ciascuno step di trasformazione, rendendo molto più semplici controlli e operazioni di debug.
Data Quality
Immaginiamo che un’operazione di ETL (Extract, Transform and Load) su diversi Terabyte di dati non vada buon fine. Ci potremmo trovare in una situazione in cui le tabelle da trasformare sono state scritte parzialmente, producendo dati corrotti che inevitabilmente vanno ad inficiare la Data Quality del nostro sistema.
Con il Delta Lake, che garantisce transazioni ACID, possiamo assicurarci che un’operazione venga eseguita in modo completo o si interrompa del tutto qualora si verifichino errori. In questo modo si possono facilmente evitare scritture di dati parziali o corrotti.
Se hai bisogno di una consulenza dedicata su uno o più servizi da noi offerti, non esistare a scriverci.
Contattaci subito
Consistenza dei dati
Per consistenza intendiamo in questo caso l’assenza di contraddizioni tra i dati. Per esempio, in una banca la somma del saldo di fine mese precedente di un conto corrente con i movimenti passivi e attivi deve essere uguale al saldo di fine mese corrente. Questo significa che le rilevazioni dei saldi e dei movimenti devono fra loro essere coerenti. Tuttavia, spesso gli sviluppatori hanno bisogno di utilizzare logiche di business diverse quando disegnano le pipeline per gli ETL su partizioni (batch pipeline) o sui flussi continui di dati (streaming pipeline). Questo fenomeno è spesso causa di problemi di incoerenza fra i dati a causa delle logiche e delle tecnologie diverse che possono essere impiegate nelle due casistiche. Con il Delta Lake le stesse funzioni possono essere applicate sia alle pipeline di batch che a quelle di streaming, ed è possibile garantire che cambiamenti nelle logiche di business siano incorporati in modo coerente nel punto in cui confluiscono i dati. In più, grazie al Delta Lake è possibile eseguire più operazioni di lettura e scrittura dei dati contemporaneamente, garantendo altresì la consistenza del risultato finale.
Data Versioning
Immaginiamo di avere un Data Lake a disposizione per gli esperimenti di Analisi Predittiva. In un contesto simile, è facile che i dati subiscano diverse trasformazioni ogni volta che i Data Scientist necessitano di modificare i parametri dei dati per i propri esperimenti. Normalmente, se si vuole mantenere la versione precedente dei dati sarà necessario farne una copia ogni volta che si intende cambiare i parametri per un esperimento e questo è decisamente un problema se si parla di volumi di dati molto elevati.
Nel Delta Lake tale problema viene risolto grazie al versioning, che permette agli utenti di accedere facilmente a tutte le versioni della tabella attraverso il transaction log, senza la necessità di creare una copia “fisica” del dataset.
Questa feature può risultare estremamente utile anche per correggere errori commessi in fase di insert o update o per rispristinare la situazione precedente a operazioni di delete.
Schema Enforcement e Schema Evolution
Quando si parla di Data Lake si cita spesso tra i suoi vantaggi la flessibilità rispetto a soluzioni più tradizionali. Tuttavia, è bene ricordare che l’adattamento ai cambiamenti nei dati non è automatico, ma deve essere predisposto nel modo appropriato. Con fonti che possono cambiare molto velocemente è necessario prevenire scritture dei dati che generino problemi di incompatibilità o dati corrotti. In questo senso, il Delta Lake utilizza il cosiddetto “Schema Enforcement” che verifica, prima di ogni operazione di scrittura, che i nuovi dati siano compatibili con lo schema della tabella target, segnalando l’errore e arrestando l’intera operazione (evitando quindi scritture parziali) qualora vi sia un mismatch. Per esempio, se si intende aggiungere un campo ridondante ad una tabella esistente, lo schema enforcement bloccherà la scrittura, garantendo la consistenza della tabella iniziale.
Allo stesso tempo, può essere necessario modificare lo schema delle tabelle ogni volta che vi siano cambiamenti nei dati. Nel Delta Lake, la flessibilità è garantita grazie alla feature “Schema Evolution”, che consente di modificare facilmente lo schema iniziale per accogliere i dati nel nuovo formato, senza la necessità di dichiararlo esplicitamente.
Concludendo, potremmo dire che grazie alle caratteristiche appena descritte la tecnologia di Databricks Delta (Delta Lake) può rappresentare la soluzione migliore per qualsiasi impresa che necessiti di costruire un Data Lake ex novo o di aggiornare il suo Data Lake esistente, sia esso sviluppato on-premises o nel cloud. Se hai bisogno di ulteriori informazioni o necessiti di una consulenza specifica per la tua azienda non esitare a contattarci.
Per approfondire:
- Business Intelligence SaaS: la BI smart e accessibile ovunque
- Data Warehouse vs. Data Lake: scegliere l’infrastruttura giusta per i tuoi dati
- Come sviluppare una cultura aziendale guidata dai dati (Data-driven)
[1] Armbrust, Chambers and Zaharia (2017). Databricks Delta: A Unified Data Management System for Real-time Big Data. Databricks blog.
Comments are closed.