


Sommario
Reinforcement Learning: di cosa si tratta?
Il Reinforcement Learning (RL), letteralmente Apprendimento per rinforzo, è una branca del Machine Learning che prevede l’allenamento di agenti “intelligenti” attraverso sistemi di ricompense e punizioni.
In questo caso, l’agente opera con una logica razionale di tipo massimizzante: in un problema sequenziale, che prevede diverse scelte consecutive, l’agente di AI cerca di massimizzare la propria utilità ad ogni step decisionale.
In altre parole, per allenare un modello di Reinforcement Learning si lascia al computer la libertà di procedere per tentativi, premiando i comportamenti corretti (quelli che aumentano il punteggio) e punendo quelli scorretti. In questo modo il modello imparerà quali azioni deve intraprendere per risolvere un problema sequenziale e quali invece è meglio evitare, in un percorso di apprendimento simile a quello di un essere umano.
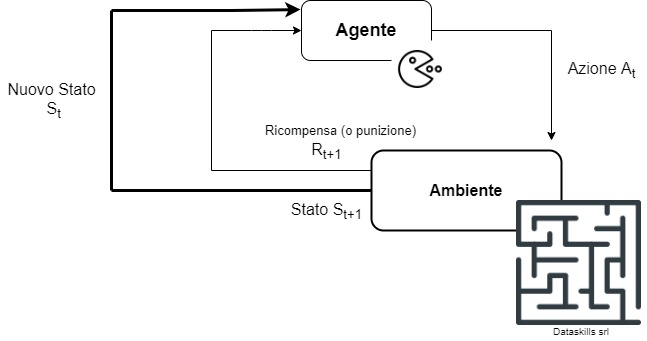
Esempio semplice di algoritmo di Reinforcement Learning
Insieme al Supervised Learing (Apprendimento supervisionato) e all’Unsupervised Learning (Apprendimento non-supervisionato), il Reinforcement Learning costituisce una delle tre principali famiglie di algoritmi per il Machine Learning.
A differenza dei primi due, tuttavia, nell’Apprendimento di rinforzo tipicamente non abbiamo né un supervisore umano che interviene direttamente nel training, né una totale assenza di supervisione.
Per esempio, se ci troviamo di fronte a un problema di classificazione con le classi corrette già note (es. prodotto difettoso vs. prodotto non difettoso), potrebbe essere più efficiente sviluppare un modello di Apprendimento supervisionato, poiché saremo in grado di valutare in modo rapido la correttezza della prediction offerta dal modello.
Viceversa, se non vi è una particolare variabile target da stimare ma si sta semplicemente cercando di estrapolare possibili pattern dai dati di input (ad esempio, se si vuole scoprire qual è la variabile che maggiormente differenza i clienti di un’azienda gli uni dagli altri), allora la scelta migliore può essere quella di un algoritmo di apprendimento non supervisionato.
Il Reinforcement Learning invece si rivela più vantaggioso per problemi di scelta sequenziali con esito incerto o molto dispendioso da verificare (si pensi ad esempio ad una partita di scacchi dove si dovrebbe impiegare tantissimo tempo a calcolare ogni possibile variante per ciascuna mossa), poiché il modello è in grado di imparare “da sé” ad attuare le scelte migliori.
Reinforcement Learning e Videogiochi
Per questo tipo di algoritmi i videogiochi rappresentano un ottimo banco di prova per il training dei modelli. Ciascun gioco può essere infatti visto come un ambiente dove ad ogni stato corrisponde un diverso insieme di scelta. Il modello di Reinforcement Learning dovrà quindi compiere delle azioni che vadano a massimizzare il suo punteggio nel gioco, valutando opportunamente se reiterare comportamenti passati che hanno condotto ad una ricompensa o se intraprendere una nuova via seppur dal risultato incerto (un trade-off noto anche come exploitation vs. exploration).
Nel campo della ricerca sull’Intelligenza Artificiale sono stati numerosi gli esperimenti che hanno previsto l’impego di ambienti videoludici per il training degli agenti. Numerosi esempi recenti provengono da DeepMind, società all’avanguardia nella ricerca sull’AI acquisita da Google nel 2014, che ha utilizzato videogiochi come Quake III Arena e StarCraft II per allenare le proprie istanze di Intelligenza Artificiale. In particolare, in un esperimento condotto nel 2019 all’interno del gioco Capture the Flag di Quake III Area, è stato eseguito il training di una popolazione di agenti AI, ciascuno con il proprio percorso di apprendimento indipendente, in modo da testare la capacità di cooperazione dell’AI sia tra gli agenti stessi sia con giocatori umani. I risultati dell’esperimento hanno mostrato degli agenti AI in grado non solo di performare nettamente meglio dei giocatori umani più abili, ma anche di dimostrare un miglior grado di cooperazione all’interno del gioco.
Un’altra società di ricerca, Open AI, ha invece utilizzato il videogioco Dota 2 per allenare i suoi modelli di Intelligenza Artificiale nel progetto OpenAI Five. L’obiettivo di lungo periodo è quello di aumentare sempre di più la capacità di generalizzazione dei modelli per realizzare quella che viene definita come Intelligenza Artificiale Generalizzata (o AGI, Artificial General Intelligence), ossia un’intelligenza “completa”, come quella degli esseri umani, in grado di interagire in un sistema complesso come quello del mondo reale. Gli agenti di OpenAI, allenati attraverso il Reinforcement Learning, sono stati in grado di battere sia una squadra di amatori che di semi-professionisti di Dota 2, mettendo inoltre in difficoltà un team di professionisti scelti tra i più forti giocatori del videogame.
Una partita di Dota 2, il gioco è stato scelto per la sua popolarità su Twitch e per la sua compatibilità con Linux
Data l’elevata complessità del gioco (che si gioca a squadre in 5 contro 5), alcuni esperti di AI hanno parlato dell’esperimento come di un grande successo nello sviluppo dell’Intelligenza Artificiale, mentre altri hanno criticato il fatto che i bot siano stati fortemente privilegiati dall’accesso diretto alle API del gioco, quando avrebbero dovuto utilizzare sistemi di Computer Vision per interpretare i pixel dello schermo.
Gli stessi modelli di RL utilizzati per Dota 2 sono in seguito stati impiegati da OpenAI per realizzare un braccio robotico che è stato in grado di imparare a risolvere in modo autonomo il cubo di Rubik, resistendo inoltre a operazioni di “disturbo” mai incontrate nella fase di training.
Applicazioni pratiche del Reinforcement Learning
Oltre che per fini di ricerca gli algoritmi di Reinforcement Learning sono già impiegati da alcuni anni in diversi ambiti pratici.
Vediamone alcuni:
1. Energia
La già citata DeepMind grazie ai suoi algoritmi di RL ha permesso a Google di ottimizzare i sistemi di raffreddamento dei suoi datacenter, portando ad un risparmio del 40% del consumo energetico.
2. Automazione Industriale
La giapponese Fanuc, ad esempio, ha realizzato un braccio meccanico in grado di imparare a raccogliere e spostare oggetti. Il vantaggio in questo caso risiede nel fatto che la progettazione di un robot “tradizionale”, senza l’utilizzo di tecniche di RL, richiede un’estrema precisione in fase di programmazione per ottenere un risultato soddisfacente, mentre con il RL è il robot stesso a individuare la via migliore per svolgere i propri compiti nella maniera più efficiente, imparando a mano a mano dai propri errori.
3. Logistica
La gestione del magazzino e delle consegne è sicuramente una delle aree dove questo tipo di algoritmi si rivela più proficua, essendo i modelli in grado di operare una serie di ottimizzazioni in un ambiente estremamente complesso, con costi di implementazione relativamente contenuti.
Se hai bisogno di una consulenza dedicata su uno o più servizi da noi offerti, non esistare a scriverci.
Contattaci subito4. Finanza
Gli algoritmi di RL rappresentano un’ottima scelta in diversi ambiti afferenti ai servizi finanziari, come ottimizzazione per la gestione di portafogli, pricing di opzioni e derivati, e applicazione di strategie di trading automatizzate.
5. Sanità
I sistemi di RL sono stati impiegati in dispositivi medici per aiutare ad individuare alcuni tipi di patologie o per fornire suggerimenti per possibili terapie sulla base dei dati raccolti sul paziente.
Conclusione
In questo articolo abbiamo introdotto gli algoritmi di Reinforcement Learning, mostrandone alcuni esempi nella ricerca e nel business.
Questo tipo di soluzioni ha un grande potenziale per il futuro e già oggi può permettere di ottenere risultati significativi in diversi ambiti di applicazione. Tuttavia, è importante sottolineare che tale tipo di approccio necessita sicuramente di una forte attenzione alla qualità dei dati, e di un’attenta pianificazione a seconda del problema che si intende andare a risolvere. In un contesto come quello attuale, dove i dati evolvono rapidamente, sia per natura che per dimensioni, la presenza di distorsioni o il cambiamento di particolari variabili nell’ambiente di riferimento può portare il modello a produrre risultati non sempre soddisfacenti. Avere le giuste competenze è inoltre fondamentale per realizzare progetti di successo in quest’ambito. Se sei interessato a ottenere maggiori informazioni su questo tipo di soluzioni non esitare a contattarci.
Per approfondire:
- Data Lake: cos’è, a cosa serve e come si differenzia dal Data Warehouse
- Gli step da seguire per potenziare la tua azienda con l’Intelligenza Artificiale
- Machine Learning per la Manutenzione Predittiva: esempi di applicazione nell’Industria 4.0
Fonti:
Jaderberg et al. (2019). Human-level performance in 3D multiplayer games with population-based reinforcement learning. Science Vol. 364, Issue 6443, pp. 859-865.
Will Knight (2018). A team of AI algorithms just crushed humans in a complex computer game. MIT Technology Review.
Will Knight (2016). This Factory Robot Learns a New Job Overnight. MIT Technology Review.
OpenAI (2019). Solving Rubik’s Cube with a Robot Hand.
Comments are closed.